
Important KPIs and Server Monitoring Metrics
 Updated Nov 2022: Additional links were added to this article and the content reviewed as up to date.
Updated Nov 2022: Additional links were added to this article and the content reviewed as up to date.
IT applications are vital for today’s digital economy and for the business to succeed, these applications must be highly available and performing well. Application performance degradations can occur for several reasons. There may be code-level issues, database slowness, or network bandwidth constraints. IT applications run on servers and if the server is not sized correctly or is under-performing, application performance will degrade as well. Therefore, it is vitally important to monitor the performance of all the servers in your data center. In this blog, we will explore what the most important metrics for server monitoring are and why.
 Historically, the key factors affecting server performance have been utilization of server CPU and memory resources. If the CPU usage of a server is highly utilized (close to 100%) or there is high memory utilization (so there is very little free memory available on the server), the performance of applications running on that server will degrade. IT administrators should also be able to determine what are the top CPU and memory-consuming processes on the server so that they can troubleshoot and fix the resource usage issue quickly.
Historically, the key factors affecting server performance have been utilization of server CPU and memory resources. If the CPU usage of a server is highly utilized (close to 100%) or there is high memory utilization (so there is very little free memory available on the server), the performance of applications running on that server will degrade. IT administrators should also be able to determine what are the top CPU and memory-consuming processes on the server so that they can troubleshoot and fix the resource usage issue quickly.
 While CPU and memory monitoring are no doubt important, as server operating systems have evolved, it is important to track several other performance indicators about server operating systems that can be indicative of performance bottlenecks. This blog highlights 10 key performance indicators other than CPU and memory utilization that need to be monitored regarding server performance. These KPIs apply for any type of server, irrespective of the operating system it is running – whether Microsoft Windows, IBM AIX, HPUX, Linux variants, Oracle Solaris, etc.
While CPU and memory monitoring are no doubt important, as server operating systems have evolved, it is important to track several other performance indicators about server operating systems that can be indicative of performance bottlenecks. This blog highlights 10 key performance indicators other than CPU and memory utilization that need to be monitored regarding server performance. These KPIs apply for any type of server, irrespective of the operating system it is running – whether Microsoft Windows, IBM AIX, HPUX, Linux variants, Oracle Solaris, etc.
10 Areas of Server Monitoring that are as important as CPU and Memory Monitoring |
|---|
| 1 | Monitoring Server Uptime |
 Uptime is the amount of time for which a system has been up and operational. Uptime can be measured since the system last booted. It can be measured during each polling cycle as well. Monitoring uptime is important because:
Uptime is the amount of time for which a system has been up and operational. Uptime can be measured since the system last booted. It can be measured during each polling cycle as well. Monitoring uptime is important because:
- This metric can alert you to a situation where the system is currently operational but may have gone down and rebooted recently (e.g., you may have inadvertently configured the system to auto-apply OS updates and the system may have rebooted in the middle of a workday, and thus impacting users).
- Many organizations have a practice of rebooting systems periodically. By monitoring system uptime, administrators can get notified if a system has failed to reboot during the configured reboot cycle.
You may like to read an overview of Server Uptime Monitoring, see: What is Server Uptime Monitoring? (eginnovations.com).
| 2 | Monitoring Disk Activity |
 The disk subsystem of a server is almost as important as the compute and memory subsystems. Disk activity is the amount of time that a disk drive is actively processing requests. There are several key metrics about the disk subsystem that must be monitored:
The disk subsystem of a server is almost as important as the compute and memory subsystems. Disk activity is the amount of time that a disk drive is actively processing requests. There are several key metrics about the disk subsystem that must be monitored:
- Disk busy time indicates the percentage of time that the disk is active. If this value approaches 100%, expect requests that are accessing the disk to start queueing up. From a diagnosis perspective, it is important to know whether a disk is busy due to read or write operations.
- IOPs: I/O operations to the disk reflect the workload on the disk drive. Tracking the workload over time can help identify times when the disk subsystem is experiencing heavy load.
- Disk read/write times: This represents the time taken to read/write blocks from the disk. The lower the value, better the performance.
- Disk queue length: When a disk is not able to cope up with the requests it is receiving, additional requests are placed in the disk queue. For best performance, the disk queue length should be less than 100. This keeps the time spent by a request when it is waiting to be serviced to a minimum.
- Split IOPs: Splitting of a file is often performed to better utilize disk space. This process often results in the disk having to spend more time and I/O resources in servicing requests. This is because, splitting scatters a file across blocks, forcing the disk to perform multiple read/write operations to service a request. This, in turn, significantly increases the disk I/O activity on a server, thereby slowing down critical operations. By monitoring the amount of split I/O on a disk, an administrator can proactively capture a condition where a disk is heavily fragmented.
 While it is important to monitor how the disk subsystem is performing, for additional diagnosis, it is important to track disk activity at the file level. For example, to determine which files are seeing the highest amount of I/O activity. Monitoring tools, such as eG Enterprise have the ability to detect and report on file level I/O activity that can affect application performance.
While it is important to monitor how the disk subsystem is performing, for additional diagnosis, it is important to track disk activity at the file level. For example, to determine which files are seeing the highest amount of I/O activity. Monitoring tools, such as eG Enterprise have the ability to detect and report on file level I/O activity that can affect application performance.Monitoring the performance of the disk subsystem is extremely important for workloads that are heavily I/O intensive. For example, database servers and file servers make extensive use of disk resources and hence, it is especially important to review disk subsystems performance metrics closely for such servers.

| 3 | Monitoring Page File Usage |
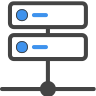
 The paging file of an OS extends its memory capacity. Data that has not been used or accessed recently is stored in the paging file. Additionally, operations that exceed the limited RAM space of the OS are automatically sent to the paging file to be stored. Ideally, the paging file size should be 1.5 times the physical memory of the server at a minimum and up to 4 times the physical memory at the most to ensure system stability.
The paging file of an OS extends its memory capacity. Data that has not been used or accessed recently is stored in the paging file. Additionally, operations that exceed the limited RAM space of the OS are automatically sent to the paging file to be stored. Ideally, the paging file size should be 1.5 times the physical memory of the server at a minimum and up to 4 times the physical memory at the most to ensure system stability.
It is important to monitor the paging file usage of the OS. If the usage of the paging file is close to 100%, it means that the paging file of the system is not sufficiently large.
 When the paging file usage is 90% or higher, the system and applications will not be able to function properly, and applications will experience slowness. You want your paging file to be large enough so that at any given time, only 50% to 75% of it is being used at the most although even lower numbers are preferred.
When the paging file usage is 90% or higher, the system and applications will not be able to function properly, and applications will experience slowness. You want your paging file to be large enough so that at any given time, only 50% to 75% of it is being used at the most although even lower numbers are preferred.| 4 | Monitoring Context Switches |
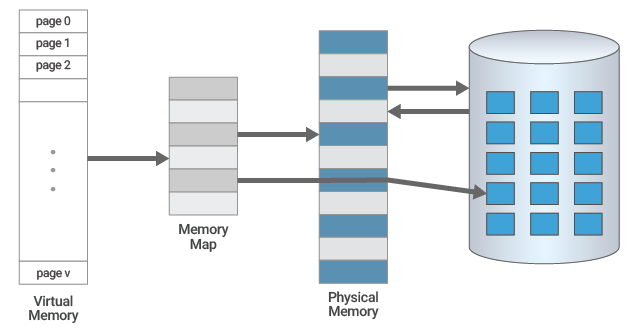
A context switch occurs when the kernel switches the processor from one process or thread to another. Context switching is generally computationally intensive. Excessive context switching takes up important CPU resources and can be one of the most expensive operations on an OS. Hence, servers must be configured and operated to avoid unnecessary context switching to the extent possible.
A high number of context switches could be due to a lot of running busy processes and a few idle ones. If CPU usage is low and context switches are high, then you will need to identify and isolate the application that is causing the context switches. It is most likely that the increased context switch rate is due to an application bug.
The figure below shows the context switches on a server tracked over a week. In this example, an application upgrade happened right around the time that the context switch rate of the server increased almost four-fold. If such a change were to happen on all the virtual machines (VMs) running on a hypervisor, the impact on the hypervisor’s compute utilization would be dramatic. A server monitoring tool must be able to identify and alert administrators to such anomalies. In this example, the increased context switch rate was due to a bug in the application that was upgraded.
| 5 | Monitoring Time Synchronization |
 When multiple systems on the same network share files or communicate with one another, different activities they perform may be time-bound or may need to be performed in sequence. System clocks are often used for this purpose and if the system clocks on different systems do not reflect the same time, the results could be disastrous.
When multiple systems on the same network share files or communicate with one another, different activities they perform may be time-bound or may need to be performed in sequence. System clocks are often used for this purpose and if the system clocks on different systems do not reflect the same time, the results could be disastrous.
For example, if machines share files over a local network, their clocks should be synchronized to determine when exactly the files were modified. Inaccurate clocks could create version conflicts or cause data to be overwritten. In a Microsoft Windows domain, timestamps are used for resolving Active Directory replication conflicts. Kerberos authentication is also heavily dependent on timestamps. Timestamps are used to protect against replay attacks—where an authentication packet is intercepted on the network and then resent later to authenticate on the original sender’s behalf. When a Windows server receives a Kerberos authentication request, it compares the timestamp in the request to its local time. If the difference between the local time and the timestamp is too big, the authentication request is rejected and Kerberos authentication fails. For Kerberos to work correctly, the clocks on all the systems in a Windows domain must be synchronized.
 Monitoring tools must monitor clock offsets of a system with respect to a reference clock, e.g., an Active Directory server’s clock. While small offsets are often acceptable, if there is a large offset between any system’s clock and the reference clock, administrators need to be alerted to such abnormalities.
Monitoring tools must monitor clock offsets of a system with respect to a reference clock, e.g., an Active Directory server’s clock. While small offsets are often acceptable, if there is a large offset between any system’s clock and the reference clock, administrators need to be alerted to such abnormalities.| 6 | Monitoring Usage of Handles |
We tend to think of CPU, memory, and disk as the main resources on a server. There are other forms of resources too – file descriptors, network sockets, processes, jobs, etc. All these resources are finite as well – there are only a limited number of files that can be open at the same time on a server. The term handle is used to refer to a resource that applications reference.
Applications are expected to request and receive resources, to use them, and then return them to the OS. A handle leak occurs when an application does not return the handle after use to the OS. One cause of a handle leak is a program error – a developer opening a file object but forgetting to close it. Handle leaks can also be caused by exceptions. Exception blocks may not have the cleanup routines that the main block of code has included.

Frequent/repeated occurrences of handle leaks over an extended period imply that many handles may be marked in-use and thus unavailable. This can cause the server performance to degrade or may even cause it to crash.
 To avoid such disasters, administrators must track handle usage over time. If the count of open handles increases consistently, it is indicative of a handle leak. Administrators may want to dig deeper and even identify the processes with the maximum number of open handles. Killing such processes or patching the programs that spawned such processes can help reduce the leak.
To avoid such disasters, administrators must track handle usage over time. If the count of open handles increases consistently, it is indicative of a handle leak. Administrators may want to dig deeper and even identify the processes with the maximum number of open handles. Killing such processes or patching the programs that spawned such processes can help reduce the leak.

| 7 | Monitoring Process Activity |
Processes running on a server need to be monitored. A silent killer is a leakage of processes. For example, application starts spawning new processes regularly without exiting previously started ones. This can result in 1000s of processes running on the server. Multi-tasking across 1000s of processes can severely reduce the performance of the server. Hence, it is important to track the current process count on a server.
Resource usage per process should be monitored as well. This often helps with diagnosis: when a server is using memory excessively, which are the processes responsible for the memory leak?
| 8 | Monitoring Network Traffic |
 Server performance can also be impacted by a malfunctioning network card. Track the number of errors seen on each network interface card of the server to determine the ones that are seeing excessive packet drops.
Server performance can also be impacted by a malfunctioning network card. Track the number of errors seen on each network interface card of the server to determine the ones that are seeing excessive packet drops.
At the same time, it is important to track the bandwidth used on each interface. If the bandwidth usage is close to the maximum speed of the network interface, this can indicate a bottleneck that affects performance.
Also compare the bandwidth used on each interface and make sure that network traffic is being routed through the primary interface you expect to use. Excessive traffic over a backup interface may indicate a routing table issue on the server that must be resolved.
| 9 | Monitoring TCP Activity |
 Most common enterprise applications are connection-oriented, and TCP is the transport protocol that they use. Therefore, performance of the TCP layer can affect application performance.
Most common enterprise applications are connection-oriented, and TCP is the transport protocol that they use. Therefore, performance of the TCP layer can affect application performance.
HTTP, SMTP, SQL and other types of connections use TCP underneath. So, when TCP performance degrades, so does the performance of applications that use them.
To track TCP performance, it is important to monitor the following metrics:
- The rate of connections to and from the server. Not only does this indicate the workload on the server, it may also be indicative of times when the server is under attack.
- Connection drops on the server should be tracked. Excessive connection drops may be a cause for concern.
- Probably, the most important performance metric to track for TCP is the percentage of retransmissions For good TCP performance, retransmissions should be at a minimum. A value up to 5% may be acceptable, but any number over 10% can significantly impact application latency and throughput. Retransmissions occur when a segment is sent by the server, but an acknowledgement is not received by the server from the client. In that case, the server has to retransmit the segment after a timeout period.
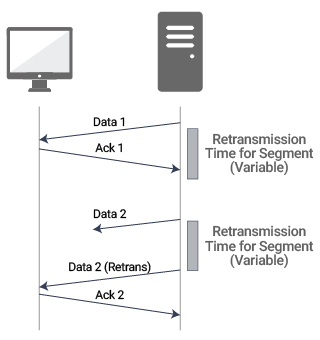
 Retransmissions are not just harmful because they involve timeouts and retransmission. TCP uses a windowing mechanism. The window represents the number of segments sent that have yet to be acknowledged. During normal transmission, the window size doubles as the sender receives acknowledgements. But when a retransmission happens, the window size contracts by half. Repeated retransmissions can result in a severe reduction in throughput.
Retransmissions are not just harmful because they involve timeouts and retransmission. TCP uses a windowing mechanism. The window represents the number of segments sent that have yet to be acknowledged. During normal transmission, the window size doubles as the sender receives acknowledgements. But when a retransmission happens, the window size contracts by half. Repeated retransmissions can result in a severe reduction in throughput.Compare retransmissions across groups of servers. If multiple servers are experiencing high retransmissions, this may be a signal that the issue is network related. Otherwise, the issue may be specific to a server and its configuration, e.g., a faulty NIC card.
| 10 | Monitoring OS Log Files |
 It is not possible to fully instrument every component of a server operating system. Details of any faults experienced, crashes seen, and other types of abnormalities are logged by the operating systems in logs.
It is not possible to fully instrument every component of a server operating system. Details of any faults experienced, crashes seen, and other types of abnormalities are logged by the operating systems in logs.
Microsoft Windows has System, Security, and Application log files. Events of different types and from different sources are logged here. Events are marked as being verbose, informational, warning, or critical.
On Unix servers too, system log and cron log files stored in the /var/log directory provide insights into abnormal events that have occurred on the server. Syslog is another common form of logging operating system anomalies.
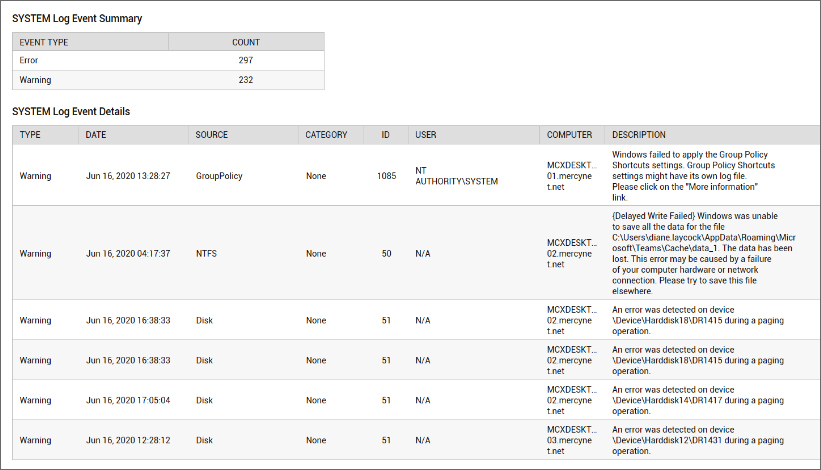 It is not possible for administrators to manually analyze logs from 100s of servers to identify issues. Periodic monitoring, analysis and alerting of log events can bring abnormalities on the server to light. Examples of problems that can be detected by using log monitoring include:
It is not possible for administrators to manually analyze logs from 100s of servers to identify issues. Periodic monitoring, analysis and alerting of log events can bring abnormalities on the server to light. Examples of problems that can be detected by using log monitoring include:
- Repeated crashes of an application or a faulty library
- Failed logons to a server
- Disk read failures due to a faulty disk drive
- Failure to apply group policies
- DNS name resolution failures
- Printing issues
- Security-related errors
- Time synchronization issues
- Patch update failures
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.
Conclusion
In conclusion, it should be clear from the above discussion that server performance monitoring must focus on much more than just CPU, memory, and disk space utilization. The basic principles discussed in this blog apply for any server operating system. Having a comprehensive server monitoring and management strategy is the first and foremost step to ensure that your IT infrastructure and the applications it supports are working well.
eG Enterprise is an Observability solution for Modern IT. Monitor digital workspaces,
web applications, SaaS services, cloud and containers from a single pane of glass.




