What is Apache Kafka?
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. It is designed for handling real-time data streams and is often used in large-scale, distributed, and data-intensive applications. Kafka is used for messaging, monitoring and metrics collection, logging, website activity tracking, real-time analytics and many other use cases.
Kafka is often chosen for large scale or high-volume message processing applications since it is more robust and reliable and offers better fault-tolerance when compared to some other message queue technologies. Interest in Kafka has been driven in a large part by its suitability for facilitating communication between microservices in distributed systems and containerized architectures or frameworks (such as Kubernetes).
Unlike messaging technologies such as RabbitMQ, Kafka does not use AMQP or other standard protocols for communication. Instead, it uses a proprietary binary TCP-based protocol that is optimized for efficiency and relies on a "message set" abstraction that naturally groups messages together to reduce the overhead of the network roundtrip. More information on the Kafka wire protocol can be found here, Apache Kafka Wire Protocol.
Kafka is used by thousands of companies including over 80% of the Fortune 100, details of Kafka usage are provided on the Kafka website: Apache Kafka Usage.
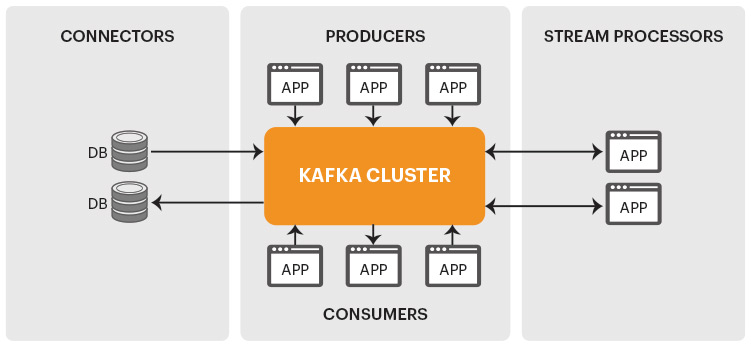
The Kafka architecture – How it works
Key features and components of Apache Kafka include:
- Publish-Subscribe Model: Kafka follows a publish-subscribe messaging model (often called “pub/sub”). Producers publish data to Kafka topics, and consumers subscribe to these topics to receive data updates.
- Topics: Topics in Kafka are logical channels or categories that data is organized into. Producers publish data to specific topics, and consumers subscribe to topics of interest.
- Partitions: Topics can be divided into partitions, allowing Kafka to parallelize data processing and distribution.
- Brokers: Kafka brokers are the servers that manage the storage and distribution of data. Multiple brokers form a Kafka cluster for fault tolerance and scalability.
- ZooKeeper: Kafka uses Apache ZooKeeper for distributed coordination and management of broker nodes in a cluster. ZooKeeper keeps the state of the cluster (brokers, topics, users).
- Producers: Producers are applications or systems that send data to Kafka topics.
- Consumers: Consumers are applications or systems that subscribe to Kafka topics to process and consume data.
- Kafka Streams: Kafka Streams is a library for building real-time data processing applications that can process, transform, and analyze data within the Kafka ecosystem.
- Connectors: Kafka Connect is a framework for integrating Kafka with external data sources and sinks, simplifying the process of getting data in and out of Kafka.
- Durability and Replication: Kafka provides data durability by replicating data across multiple brokers, ensuring that data is not lost even in the event of failures.
Apache Kafka is implemented in Java and runs on the Java Virtual Machine (JVM). Kafka's architecture is built around the JVM, with Kafka brokers being Java processes that manage message storage, replication, and data distribution. The JVM is responsible for memory management, garbage collection, and efficient execution of Kafka broker processes. Kafka's support for multiple client libraries allows developers to use Kafka with various programming languages, not just Java.
Proper configuration and tuning of the JVM are essential for ensuring Kafka's reliability and performance. Any monitoring tool used for Kafka monitoring needs to cover the JVM stack well. Beyond this the performance of the JVM depends on lower tiers such as the OS and hardware / cloud and those dependencies need monitoring too.
How Kafka works – An online eCommerce store
Scenario: Imagine an e-commerce website that relies on Kafka to manage its order processing and customer interactions.
- Producers: Customers visit the online shop and browse products, add items to their carts, or place orders. Each action by a customer, such as adding a product to the cart or completing a purchase, generates an event. These events are produced by the website's backend systems.
- Topics: Kafka organizes these events into topics. In this scenario, there might be topics for "Product Updates," "Cart Activity," "Order Placements," and more. For instance, when a customer places an order, an event is sent to the "Order Placements" topic.
- Brokers: Kafka brokers serve as servers that manage these topics and events. The brokers receive the events and store them. Multiple Kafka brokers work together to form a Kafka cluster, ensuring data replication and fault tolerance.
- Consumers: Various components within the online store act as consumers. These components subscribe to the relevant Kafka topics. For example, the inventory management system subscribes to the "Product Updates" topic to keep track of product availability. The order processing system subscribes to the "Order Placements" topic to process new orders.
- ZooKeeper: Kafka relies on Apache ZooKeeper for coordination and management tasks within the Kafka cluster. ZooKeeper helps maintain the broker's configuration and cluster health.
- Log Files: Inside each Kafka broker, events are stored as log files. These logs are divided into partitions, which enables parallel processing. Events related to a specific product, cart, or order might belong to separate partitions.
- Replication: Kafka replicates data across multiple brokers to ensure data durability and high availability. If one broker fails, replicas on other brokers can be used to recover the data.
- Consumer Groups: Consumer groups within the online shop's systems ensure that multiple components can process events concurrently. For instance, the payment processing system and the order fulfillment system might belong to separate consumer groups, allowing them to process orders in parallel and asynchronously.
- Retention: Kafka retains events for a configurable period. This means that even if an order is placed and processed, a customer can review their order history later.
What are the key metrics to monitor for Apache Kafka?
Monitoring Apache Kafka effectively involves tracking key metrics and aspects of your Kafka cluster to ensure optimal performance, reliability, and fault tolerance. Key categories of metrics to monitor are:
- Broker Metrics
- Host-level Broker Metrics
- Producer Metrics
- Consumer Metrics
- ZooKeeper Metrics
- Network Metrics
- JVM Metrics (especially Garbage Collection metrics)
eG Enterprise layered model allows full-stack visibility on Kafka usage
Kafka is highly resilient to broker failures, ensuring that data remains available and durable, and the system continues to operate with minimal disruption even in the presence of hardware failures or other issues. Proactive and continual monitoring will allow you to optimize your IT operations by identifying genuine faults and issues masked by Kafka’s fault-tolerance and self-correction.
What free or open-source monitoring tools can I use to monitor Apache Kafka?
Popular tools to monitor Kafka include:
- Prometheus: You can use Kafka exporters, such as the "JMX Exporter" or "Kafka Exporter," to collect Kafka-related metrics and integrate them with Prometheus for visualization and alerting.
- Grafana: It can be used in conjunction with Prometheus to create customizable dashboards for visualizing Kafka metrics and performance data.
- Confluent Control Centre: Confluent, the company behind Kafka, offers a Community Edition.
- Burrow: an open-source Kafka monitoring tool developed by LinkedIn.
- Kafdrop: Kafdrop is a web-based UI for monitoring Kafka clusters. It provides insights into topics, partitions, and consumers, making it easier to visualize Kafka data.
- Kafka Tool: Kafka Tool is a free, cross-platform graphical user interface for managing and monitoring Apache Kafka clusters.
- CMAK (previously known as Yahoo Kafka Manager) is a tool that enables engineers to manage Apache Kafka clusters for various Ops tasks and has some monitoring capabilities.
Most organizations leveraging Kafka in production need the full stack visibility and enterprise support and features offered by an enterprise monitoring product that also includes JVM / Java support and APM features. Popular third-party tools for monitoring and troubleshooting Kafka include: DataDog, Dynatrace, New Relic, AppDynamics and eG Enterprise.
What is Amazon Managed Service Kafka (MSK)?
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data. Amazon MSK provides control-plane operations, such as those for creating, updating, and deleting clusters. It lets you use Apache Kafka data-plane operations, such as those for producing and consuming data. It runs open-source versions of Apache Kafka. This means existing applications, tooling, and plugins from partners and the Apache Kafka community are supported without requiring changes to application code. You can use Amazon MSK to create clusters that use any of the supported Apache Kafka versions.
Information on monitoring and troubleshooting Amazon MSK is available, here: What is AWS Managed Service Kafka? (eginnovations.com).
Learn about eG Enterprise's comprehensive monitoring and observability for Kafka: Apache Kafka Monitoring | eG Innovations.



