Chaos Engineering is a discipline that aims to uncover weaknesses and improve the resilience of software systems by intentionally injecting controlled failures into them.
Robust, resilient IT systems are crucial to data-driven operations. Whether these systems drive internal processes or deliver customer-facing services, the need for reliability and availability remains the same. So, why would you deliberately try to break your services? Chaos engineering does just that – deliberately terminating instances in your production environments.
The key phrase is “in production environments” - Why not restrict testing to the dev environment?. Using chaos engineering principles, you introduce an important element of randomness into testing and accelerate the process of identifying single points of failure. System failures are rarely predictable, and the chaos monkey can surface issues that have not been previously considered. If you only ever test for what you think may break, other important issues may be overlooked.
In this way, random outages help to keep testing honest. The testing scripts cannot be skewed, shortened, or cheated, and every fault identified is real – you can literally see the problem and its effects.
In practice, to avoid damage to production environments, chaos engineers often start in a non-production environment and cautiously extend to production in a controlled manner.
Online video streaming service Netflix was one of the first organizations to popularize the concept of Chaos Engineering with their Chaos Monkey engine.
When Netflix began migrating to the cloud in 2010, they found a potential problem with hosted infrastructure – hosts could be terminated and replaced at any moment, potentially affecting quality of service. To ensure a smooth streaming experience, their systems needed to be able to manage these terminations seamlessly.
To assist with testing, Netflix developers created ‘Chaos Monkey’. This application runs in the background of Netflix operations, terminating production services randomly.
The Netflix Chaos Monkey is perhaps the best-known example of chaos engineering. And as cloud services mature, this chaos engineering methodology will gain in popularity. Netflix themselves have progressed and introduced “The Simian Army”, which is a suite of open-source cloud testing tools that enable developers to test the reliability, resilience, recoverability, and security of their cloud services. The army has seen Chaos Monkey joined by a host of ape and primate like friends such as Chaos Gorilla, Janitor Monkey, 10-18 Monkey (short for Localization-Internationalization, or l10n-i18n), Doctor Monkey, Latency Monkey and Conformity Monkey.
A fuller history of Chaos Engineering is covered on the Wikipedia page: Chaos engineering - Wikipedia.
Chaos Engineering is a practice that involves intentionally injecting controlled failures into a software system to uncover weaknesses and improve its resilience. The general steps involved in Chaos Engineering are as follows:
The goal of Chaos Engineering is not to cause chaos indefinitely but to create controlled chaos to learn about the system's behavior under stressful conditions and make it more resilient. By deliberately injecting failures and observing the system's response, teams can identify and fix weaknesses before they manifest as significant issues in production environments, ultimately improving system reliability and customer experience. The quality of the observability and monitoring tools in place to observe and understand the systems response are essential to success.
There are several popular tools used for Chaos Engineering, some commercial and some open-source, each with its own features and capabilities. Here are some frequently used tools:
A far broader useful community list of tools is available from GitHub - dastergon/awesome-chaos-engineering: A curated list of Chaos Engineering resources. Alongside a multitude of other Chaos Engineering resources.
Some useful developer and ITOps tools and methodologies that may be of use within a Chaos Engineering strategy or mindset are detailed in IT Infrastructure Management – Tools and Strategies (eginnovations.com). Whilst most are not dedicated Chaos tools, many are useful for kicking the tires of deployments (Wan Emulation, Fuzzing, Load Testing and other methodologies are discussed).
Increasingly cloud providers are recognizing the demand for Chaos Engineering testing from organizations running applications and services upon their cloud infrastructure and are providing services to help such workflows. For example AWF Fault Injection Simulator was released in March 2021, a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resiliency. Fault injection experiments are used in chaos engineering, which is the practice of stressing an application in testing or production environments by creating disruptive events, such as sudden increase in CPU or memory consumption, observing how the system responds, and implementing improvements. Beyond the managed service, open-sourced tools have also been released by AWS Engineering.
Microsoft Azure has a similar offering to AWS’ (as of July 2023 in preview) - Azure Chaos Studio - Chaos engineering experimentation | Microsoft Azure. The availability of such tools and services is becoming a factor when choosing between different clouds or virtualization environments.
Conducting tests on the production system is quite a high risk. Organizations usually need a relatively robust and mature platform before they can consider unleashing a tool such as the Chaos Monkey. However, there are also some benefits:
Other benefits cited are usually long-term and assume that Chaos Engineering is implemented well-enough to identify enough serious faults to justify any problems it might inadvertently cause. Benefits such as:
Whilst there are many pros for using Chaos Engineering there are also a number of cons, or at least challenges, including:
Whilst Chaos Engineering can be a valuable tool for improving system resilience and identifying weaknesses, it should be approached with caution and proper expertise. When executed effectively, it can significantly enhance a system's ability to handle failures and improve the overall customer experience. If an organization does not have the skills or maturity to implement Chaos Engineering well, it may well not be an appropriate methodology for that organization to adopt. Cloud Consultant Mathias Lafeldt’s much circulated blog is a good starting point around this decision, see: The Limitations of Chaos Engineering | Mathias Lafeldt (sharpend.io).
Beyond the well-known Netflix / Chaos Monkey implementation there are many other examples of Chaos Engineering tools and practices in use.
Some good articles covering real world use of Chaos Engineering include:
eG Enterprise offers extensive applications and platform monitoring functions, allowing you to assess current system health – and the effects of every chaos monkey-inspired failure.
Observability is an essential component of Chaos Engineering. If you are to understand the impact of a chaos engineering experiment or test, you first need to understand the steady state behavior, which means needing a monitoring baseline. Monitoring is generally difficult and complex for highly distributed, possibly auto-scaling, cloud native systems.
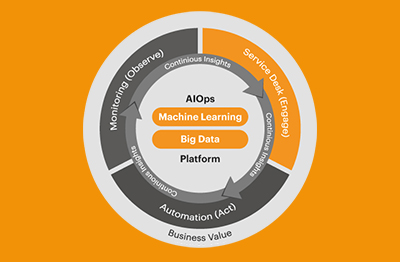
Specialist tools such as eG Enterprise are designed to enable observability and give administrators established baselines of behavior over time. Intelligent AIOps capabilities leveraging statistical algorithms alongside Machine Learning not only provide that baseline but also provide continual analysis and understanding of metrics, logs and traces as chaos engineering tests are performed to alert operators to the impacts of the experiment.
Steve Upton’s blog covers how tools with root-cause diagnostic capabilities are essential for a functioning Chaos Engineering testing, see: Four chaos engineering mistakes to avoid | Thoughtworks.
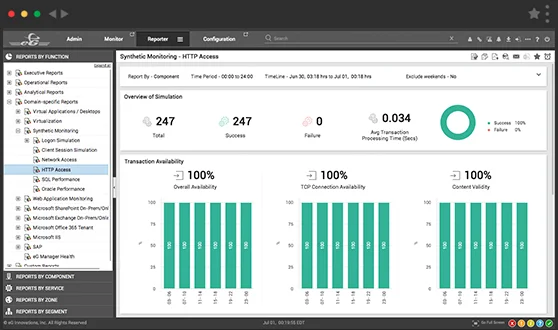
As AWS’s blog discusses, here: Verify the resilience of your workloads using Chaos Engineering | AWS Architecture Blog (amazon.com), one useful monitoring tool feature leveraged within a chaos engineering strategy is Synthetic Monitoring, allowing organizations to use robot users to test modifications rather than relying on real users encountering issues first with all the “chaos” that can bring.